* Samba with multichannel and io_uring
@ 2020-10-15 9:58 Stefan Metzmacher
2020-10-15 10:06 ` Ralph Boehme
` (2 more replies)
0 siblings, 3 replies; 11+ messages in thread
From: Stefan Metzmacher @ 2020-10-15 9:58 UTC (permalink / raw)
To: Samba Technical, io-uring
[-- Attachment #1.1: Type: text/plain, Size: 6696 bytes --]
Hi,
related to my talk at the virtual storage developer conference
"multichannel / iouring Status Update within Samba"
(https://www.samba.org/~metze/presentations/2020/SDC/),
I have some additional updates.
DDN was so kind to sponsor about a week of research on real world
hardware with 100GBit/s interfaces and two NUMA nodes per server.
I was able to improve the performance drastically.
I concentrated on SMB2 read performance, but similar improvements would be expected for write too.
We used "server multi channel support = yes" and the network interface is RSS capable,
it means that a Windows client uses 4 connections by default.
I first tested a share using /dev/shm and the results where really slow,
it was not possible to reach more than ~30 GBits/s on the net and ~ 3.8 GBytes/s
from fio.exe.
smbd uses pread() from within a pthread based threadpool for file io
and sendmsg() to deliver the response to the socket. All multichannel
connections are served by the same smbd process (based on the client guid).
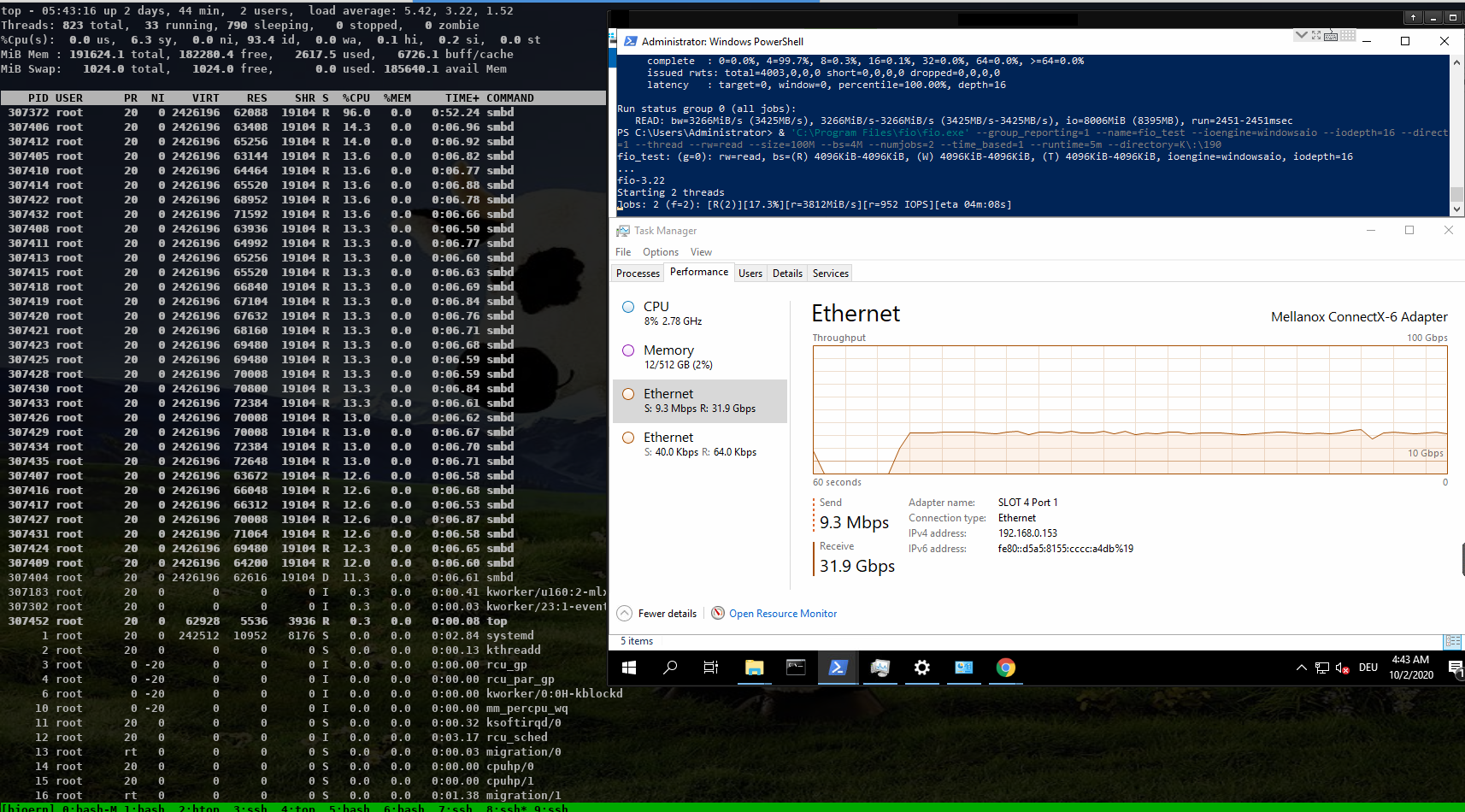
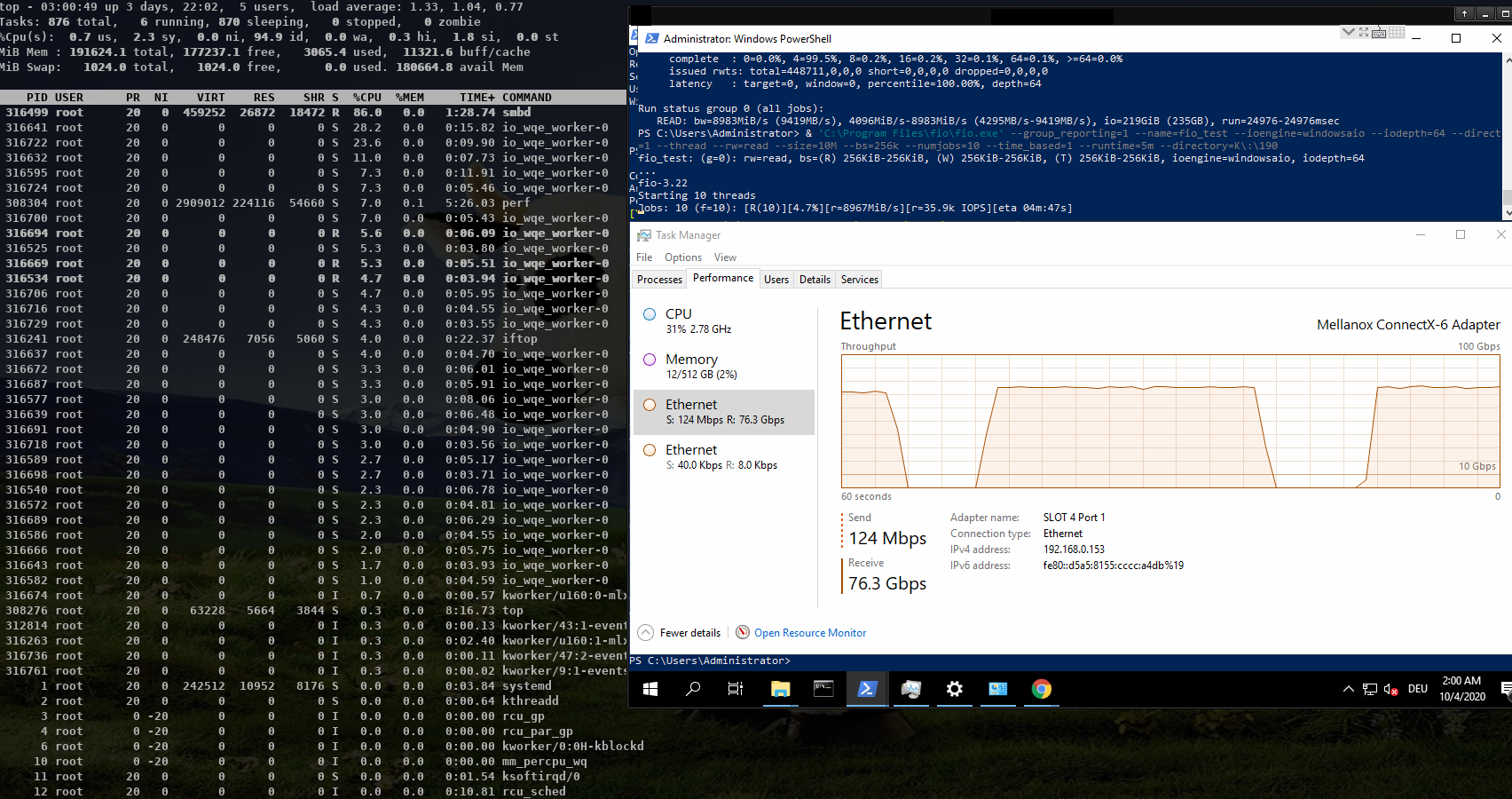
The main smbd is cpu bound and the helper threads also use quite some cpu
about ~ 600% in total!
https://www.samba.org/~metze/presentations/2020/SDC/future/read-32GBit-4M-2T-shm-sendmsg-top-02.png
It turns out that NUMA access caused a lot of slow down.
The network adapter was connected to numa node 1, so we pinned
the ramdisk and smbd to that node.
mount -t tmpfs -o size=60g,mpol=bind:1 tmpfs /dev/shm-numanode1
numactl --cpunodebind=netdev:ens3f0 --membind=netdev:ens3f0 smbd
With that it was possible to reach ~ 5 GBytes/s from fio.exe
But the main problem remains the kernel is busy copying data
and sendmsg() takes up to 0.5 msecs, which means that we don't process new requests
during these 0.5 msecs.
I created a prototype that uses IORING_OP_SENDMSG with IOSQE_ASYNC (I used a 5.8.12 kernel)
instead of the sync sendmsg() calls, which means that one kernel thread
(io_wqe_work ~50% cpu) per connection is doing the memory copy to the socket
and the main smbd only uses ~11% cpu, but we still use > 400% cpu in total.
https://www.samba.org/~metze/presentations/2020/SDC/future/read-57GBit-4M-2T-shm-io-uring-sendmsg-async-top-02.png
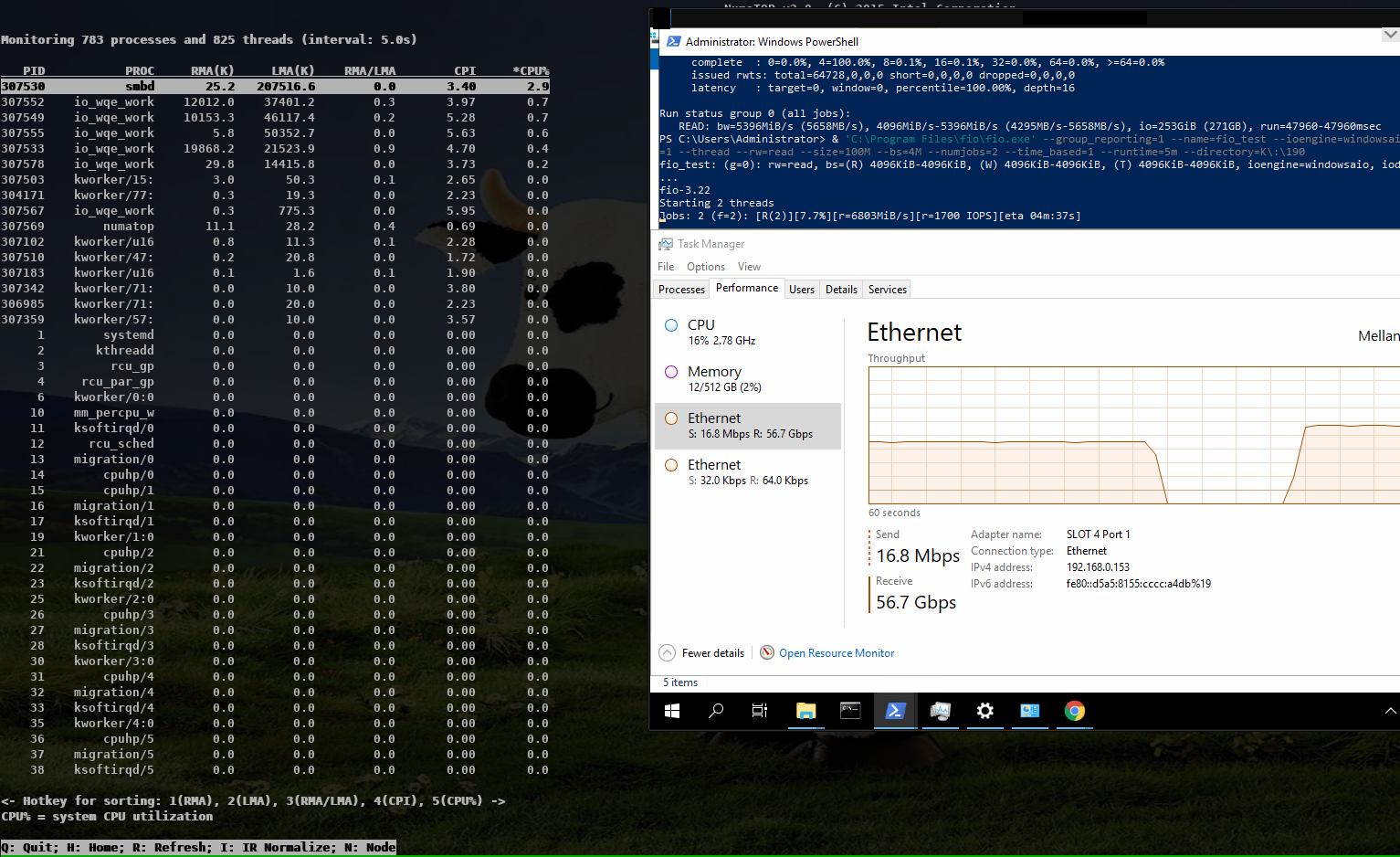
But it seems the numa binding for the io_wqe_work thread doesn't seem to work as expected,
so the results vary between 5.0 GBytes/s and 7.6 GBytes/s, depending on which numa node
io_wqe_work kernel threads are running. Also note that the threadpool with pread was
still faster than using IORING_OP_READV towards the filesystem, the reason might also
be numa dependent.
https://www.samba.org/~metze/presentations/2020/SDC/future/read-57GBit-4M-2T-shm-io-uring-sendmsg-async-numatop-02.png
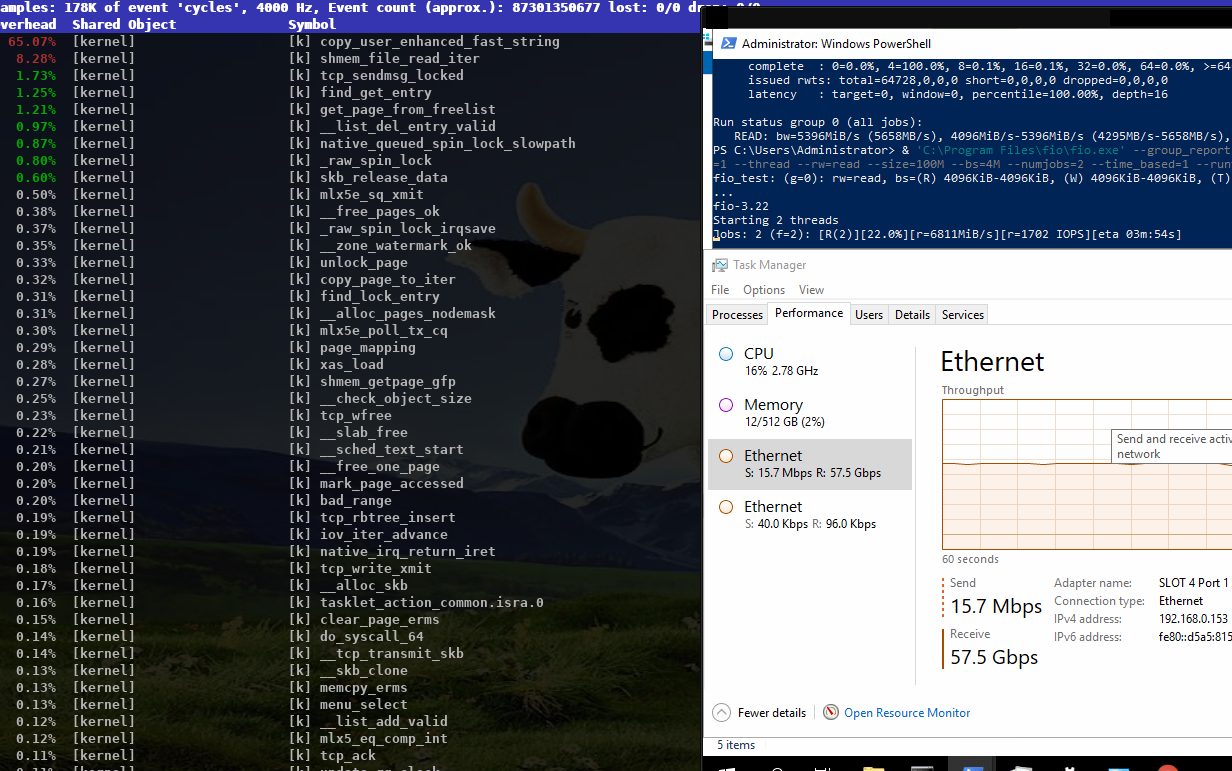
https://www.samba.org/~metze/presentations/2020/SDC/future/read-57GBit-4M-2T-shm-io-uring-sendmsg-async-perf-top-02.png
The main problem is still copy_user_enhanced_fast_string, so I tried to use
IORING_IO_SPLICE (from the filesystem via a pipe to the socket) in order to avoid
copying memory around.
With that I was able to reduce the cpu usage of the main smbd to ~6% cpu with
io_wqe_work threads using between ~3-6% cpu (filesystem to pipe) and
6-30% cpu (pipe to socket).
But the Windows client wasn't able to reach better numbers than 7.6 GBytes/s (65 GBits/s).
Only using "Set-SmbClientConfiguration -ConnectionCountPerRssNetworkInterface 16" helped to
get up to 8.9 GBytes/s (76 GBits/s).
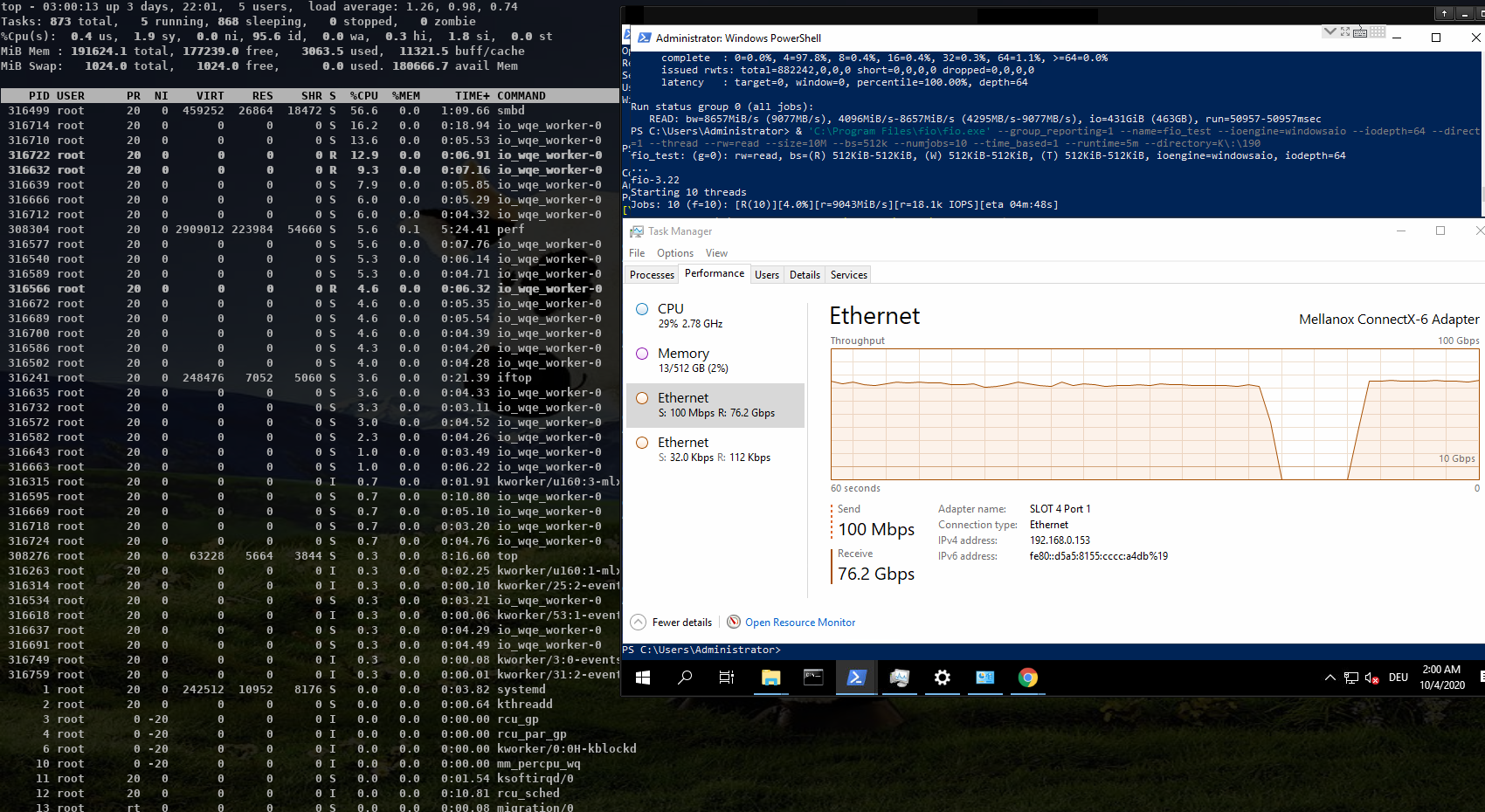
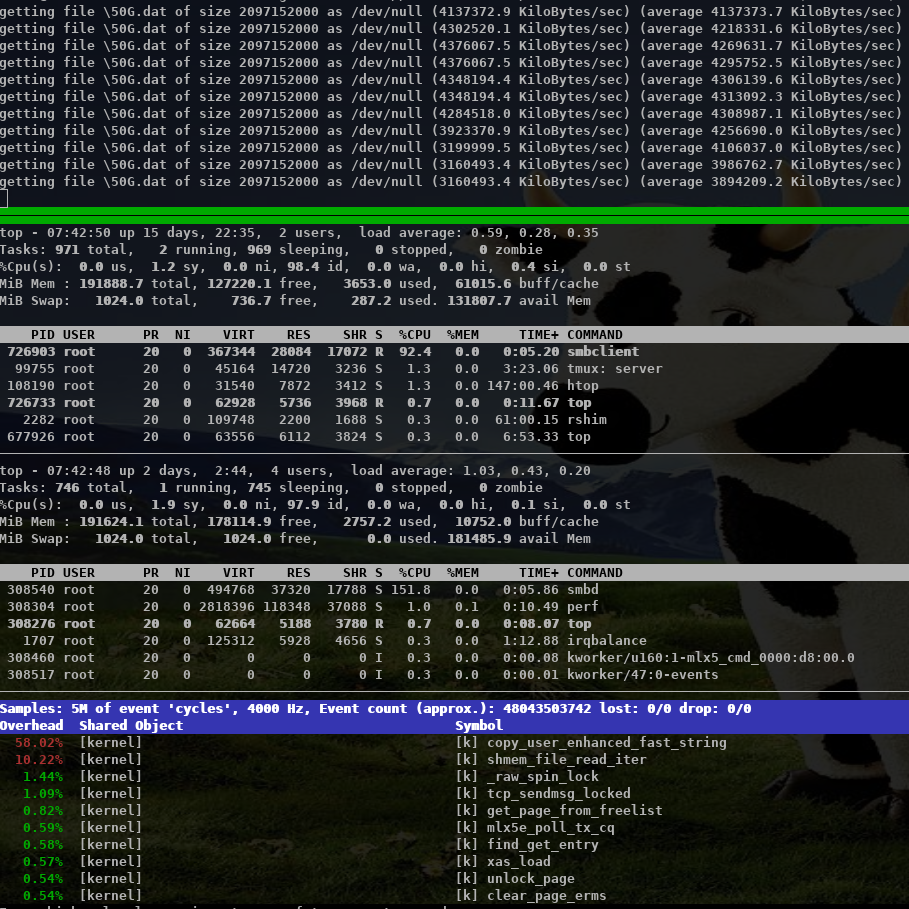
With 8 MByte IOs smbd is quite idle at ~ 5% cpu with the io_wqe_work threads ~100% cpu in total.
https://www.samba.org/~metze/presentations/2020/SDC/future/read-75GBit-8M-20T-RSS16-shm-io-uring-splice-top-02.png
With 512 KByte IOs smbd uses ~56% cpu with the io_wqe_work threads ~130% cpu in total.
https://www.samba.org/~metze/presentations/2020/SDC/future/read-76GBit-512k-10T-RSS16-shm-io-uring-splice-02.png
With 256 KByte IOS smbd uses ~87% cpu with the io_wqe_work threads ~180% cpu in total.
https://www.samba.org/~metze/presentations/2020/SDC/future/read-76GBit-256k-10T-RSS16-shm-io-uring-splice-02.png
In order to get higher numbers I also tested with smbclient.
- With the default configuration (sendmsg and threadpool pread) I was able to get
4.2 GBytes/s over a single connection, while smbd with all threads uses ~150% cpu.
https://www.samba.org/~metze/presentations/2020/SDC/future/read-4.2G-smbclient-shm-sendmsg-pthread.png
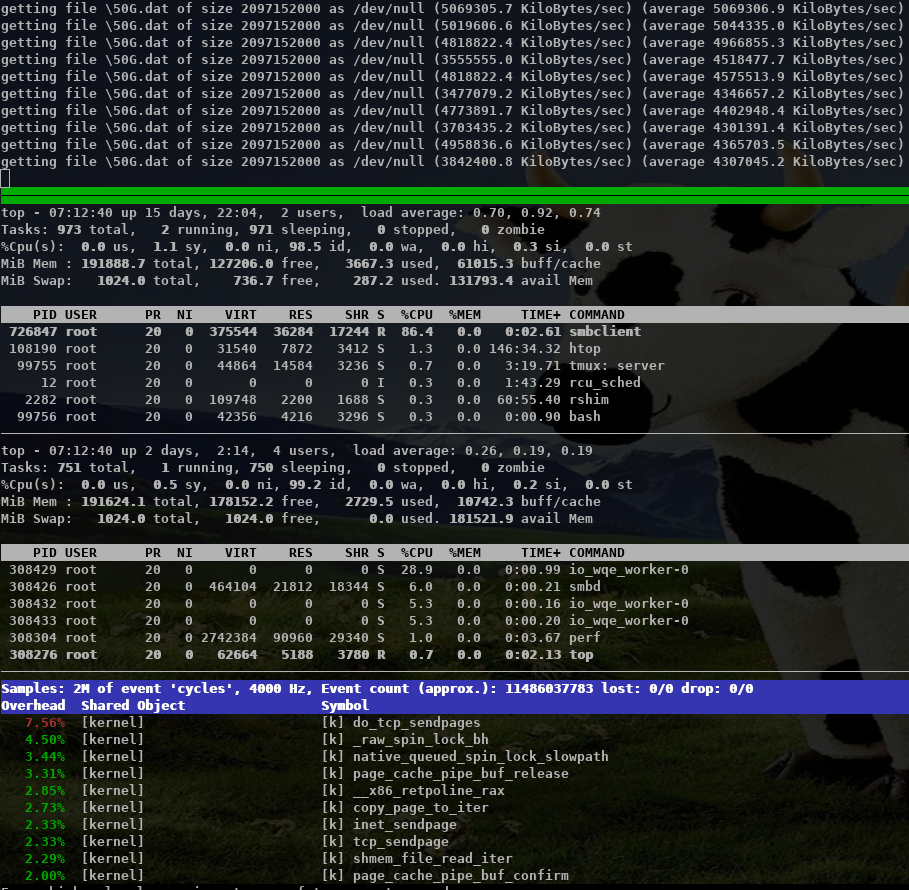
- With IORING_IO_SPLICE I was able to get 5 GBytes/s over a single connection,
while smbd uses ~ 6% cpu, with 2 io_wqe_work threads (filesystem to pipe) at 5.3% cpu each +
1 io_wqe_work thread (pipe to socket) at ~29% cpu. This is only ~55% cpu in total on the server
and the client is the bottleneck here.
https://www.samba.org/~metze/presentations/2020/SDC/future/read-5G-smbclient-shm-io-uring-sendmsg-splice-async.png
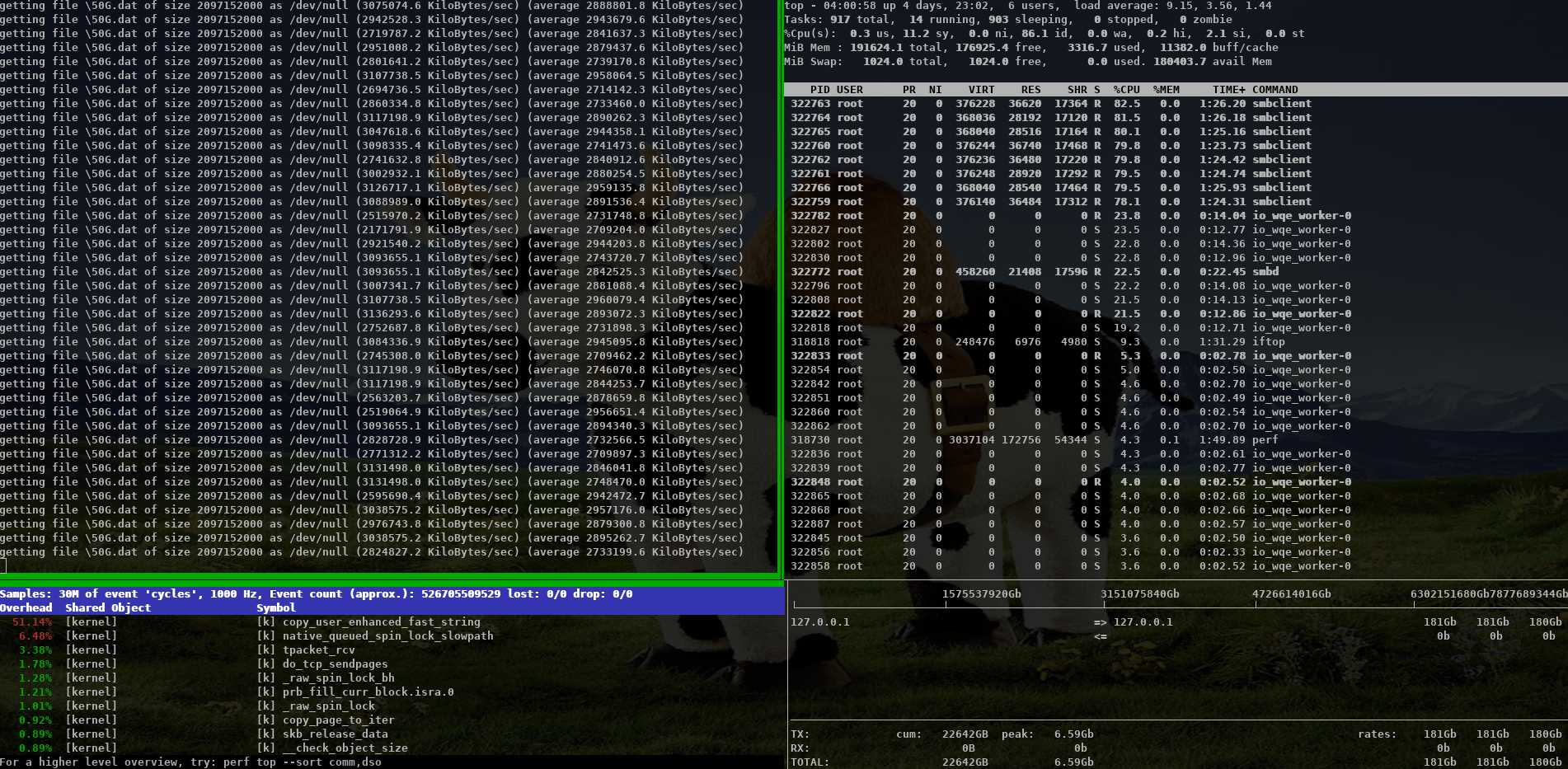
- With a modified smbclient using a forced client guid I used 4 connections into
a single smbd on the server. With that I was able to reach ~ 11 GBytes/s (92 GBits/s)
(This is similar to what 4 iperf instances are able to reach).
The main smbd uses 8.6 % cpu with 4 io_wqe_work threads (pipe to socket) at ~20% cpu each.
https://www.samba.org/~metze/presentations/2020/SDC/future/read-11G-smbclient-same-client-guid-shm-io-uring-splice-async.png
- With 8 smbclient instances over loopback we are able to reach ~ 22 GBytes/s (180 GBits/s)
and smbd uses 22 % cpu.
https://www.samba.org/~metze/presentations/2020/SDC/future/read-22G-smbclient-8-same-client-guid-localhost-shm-io-uring-splice.png
So IORING_IO_SPLICE will bring us into a very good shape for streaming reads.
Also note that numa pinning is not really needed here as the memory is not really touched at all.
It's very likely that IORING_IO_RECVMSG in combination with IORING_IO_SPLICE would also improve the write path.
Using AF_KCM socket (Kernel Connection Multiplexor) as wrapper to the
(TCP) stream socket might be able to avoid wakeups for incoming packets and
should allow better buffer management for incoming packets within smbd.
The prototype/work in process patches are available here:
https://git.samba.org/?p=metze/samba/wip.git;a=shortlog;h=refs/heads/v4-13-multichannel
and
https://git.samba.org/?p=metze/samba/wip.git;a=shortlog;h=refs/heads/master-multichannel
Also notice the missing generic multichannel things via this meta bug:
https://bugzilla.samba.org/show_bug.cgi?id=14534
I'm not sure when all this will be production ready, but it's great to know
the potential we have on a modern Linux kernel!
Later SMB-Direct should be able to reduce the cpu load of the io_wqe_work threads (pipe to socket)...
metze
[-- Attachment #2: OpenPGP digital signature --]
[-- Type: application/pgp-signature, Size: 833 bytes --]
^ permalink raw reply [flat|nested] 11+ messages in thread* Re: Samba with multichannel and io_uring 2020-10-15 9:58 Samba with multichannel and io_uring Stefan Metzmacher @ 2020-10-15 10:06 ` Ralph Boehme 2020-10-15 15:45 ` Jeremy Allison 2020-10-15 16:11 ` Jens Axboe 2 siblings, 0 replies; 11+ messages in thread From: Ralph Boehme @ 2020-10-15 10:06 UTC (permalink / raw) To: Stefan Metzmacher, Samba Technical, io-uring [-- Attachment #1.1: Type: text/plain, Size: 451 bytes --] Hey metze, Am 10/15/20 um 11:58 AM schrieb Stefan Metzmacher via samba-technical: > I'm not sure when all this will be production ready, but it's great to know > the potential we have on a modern Linux kernel! awesome! Thanks for sharing this! -slow -- Ralph Boehme, Samba Team https://samba.org/ Samba Developer, SerNet GmbH https://sernet.de/en/samba/ GPG-Fingerprint FAE2C6088A24252051C559E4AA1E9B7126399E46 [-- Attachment #2: OpenPGP digital signature --] [-- Type: application/pgp-signature, Size: 833 bytes --] ^ permalink raw reply [flat|nested] 11+ messages in thread
* Re: Samba with multichannel and io_uring 2020-10-15 9:58 Samba with multichannel and io_uring Stefan Metzmacher 2020-10-15 10:06 ` Ralph Boehme @ 2020-10-15 15:45 ` Jeremy Allison 2020-10-15 16:11 ` Jens Axboe 2 siblings, 0 replies; 11+ messages in thread From: Jeremy Allison @ 2020-10-15 15:45 UTC (permalink / raw) To: Stefan Metzmacher; +Cc: Samba Technical, io-uring On Thu, Oct 15, 2020 at 11:58:00AM +0200, Stefan Metzmacher via samba-technical wrote: > Hi, > > related to my talk at the virtual storage developer conference > "multichannel / iouring Status Update within Samba" > (https://www.samba.org/~metze/presentations/2020/SDC/), > I have some additional updates. > > DDN was so kind to sponsor about a week of research on real world > hardware with 100GBit/s interfaces and two NUMA nodes per server. > > I was able to improve the performance drastically. > > I concentrated on SMB2 read performance, but similar improvements would be expected for write too. > > We used "server multi channel support = yes" and the network interface is RSS capable, > it means that a Windows client uses 4 connections by default. > > I first tested a share using /dev/shm and the results where really slow, > it was not possible to reach more than ~30 GBits/s on the net and ~ 3.8 GBytes/s > from fio.exe. > > smbd uses pread() from within a pthread based threadpool for file io > and sendmsg() to deliver the response to the socket. All multichannel > connections are served by the same smbd process (based on the client guid). > > The main smbd is cpu bound and the helper threads also use quite some cpu > about ~ 600% in total! > > https://www.samba.org/~metze/presentations/2020/SDC/future/read-32GBit-4M-2T-shm-sendmsg-top-02.png > > It turns out that NUMA access caused a lot of slow down. > The network adapter was connected to numa node 1, so we pinned > the ramdisk and smbd to that node. > > mount -t tmpfs -o size=60g,mpol=bind:1 tmpfs /dev/shm-numanode1 > numactl --cpunodebind=netdev:ens3f0 --membind=netdev:ens3f0 smbd > > With that it was possible to reach ~ 5 GBytes/s from fio.exe > > But the main problem remains the kernel is busy copying data > and sendmsg() takes up to 0.5 msecs, which means that we don't process new requests > during these 0.5 msecs. > > I created a prototype that uses IORING_OP_SENDMSG with IOSQE_ASYNC (I used a 5.8.12 kernel) > instead of the sync sendmsg() calls, which means that one kernel thread > (io_wqe_work ~50% cpu) per connection is doing the memory copy to the socket > and the main smbd only uses ~11% cpu, but we still use > 400% cpu in total. > > https://www.samba.org/~metze/presentations/2020/SDC/future/read-57GBit-4M-2T-shm-io-uring-sendmsg-async-top-02.png > > But it seems the numa binding for the io_wqe_work thread doesn't seem to work as expected, > so the results vary between 5.0 GBytes/s and 7.6 GBytes/s, depending on which numa node > io_wqe_work kernel threads are running. Also note that the threadpool with pread was > still faster than using IORING_OP_READV towards the filesystem, the reason might also > be numa dependent. > > https://www.samba.org/~metze/presentations/2020/SDC/future/read-57GBit-4M-2T-shm-io-uring-sendmsg-async-numatop-02.png > https://www.samba.org/~metze/presentations/2020/SDC/future/read-57GBit-4M-2T-shm-io-uring-sendmsg-async-perf-top-02.png > > The main problem is still copy_user_enhanced_fast_string, so I tried to use > IORING_IO_SPLICE (from the filesystem via a pipe to the socket) in order to avoid > copying memory around. > > With that I was able to reduce the cpu usage of the main smbd to ~6% cpu with > io_wqe_work threads using between ~3-6% cpu (filesystem to pipe) and > 6-30% cpu (pipe to socket). > > But the Windows client wasn't able to reach better numbers than 7.6 GBytes/s (65 GBits/s). > Only using "Set-SmbClientConfiguration -ConnectionCountPerRssNetworkInterface 16" helped to > get up to 8.9 GBytes/s (76 GBits/s). > > With 8 MByte IOs smbd is quite idle at ~ 5% cpu with the io_wqe_work threads ~100% cpu in total. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-75GBit-8M-20T-RSS16-shm-io-uring-splice-top-02.png > > With 512 KByte IOs smbd uses ~56% cpu with the io_wqe_work threads ~130% cpu in total. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-76GBit-512k-10T-RSS16-shm-io-uring-splice-02.png > > With 256 KByte IOS smbd uses ~87% cpu with the io_wqe_work threads ~180% cpu in total. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-76GBit-256k-10T-RSS16-shm-io-uring-splice-02.png > > In order to get higher numbers I also tested with smbclient. > > - With the default configuration (sendmsg and threadpool pread) I was able to get > 4.2 GBytes/s over a single connection, while smbd with all threads uses ~150% cpu. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-4.2G-smbclient-shm-sendmsg-pthread.png > > - With IORING_IO_SPLICE I was able to get 5 GBytes/s over a single connection, > while smbd uses ~ 6% cpu, with 2 io_wqe_work threads (filesystem to pipe) at 5.3% cpu each + > 1 io_wqe_work thread (pipe to socket) at ~29% cpu. This is only ~55% cpu in total on the server > and the client is the bottleneck here. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-5G-smbclient-shm-io-uring-sendmsg-splice-async.png > > - With a modified smbclient using a forced client guid I used 4 connections into > a single smbd on the server. With that I was able to reach ~ 11 GBytes/s (92 GBits/s) > (This is similar to what 4 iperf instances are able to reach). > The main smbd uses 8.6 % cpu with 4 io_wqe_work threads (pipe to socket) at ~20% cpu each. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-11G-smbclient-same-client-guid-shm-io-uring-splice-async.png > > - With 8 smbclient instances over loopback we are able to reach ~ 22 GBytes/s (180 GBits/s) > and smbd uses 22 % cpu. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-22G-smbclient-8-same-client-guid-localhost-shm-io-uring-splice.png > > So IORING_IO_SPLICE will bring us into a very good shape for streaming reads. > Also note that numa pinning is not really needed here as the memory is not really touched at all. > > It's very likely that IORING_IO_RECVMSG in combination with IORING_IO_SPLICE would also improve the write path. > > Using AF_KCM socket (Kernel Connection Multiplexor) as wrapper to the > (TCP) stream socket might be able to avoid wakeups for incoming packets and > should allow better buffer management for incoming packets within smbd. > > The prototype/work in process patches are available here: > https://git.samba.org/?p=metze/samba/wip.git;a=shortlog;h=refs/heads/v4-13-multichannel > and > https://git.samba.org/?p=metze/samba/wip.git;a=shortlog;h=refs/heads/master-multichannel > > Also notice the missing generic multichannel things via this meta bug: > https://bugzilla.samba.org/show_bug.cgi?id=14534 > > I'm not sure when all this will be production ready, but it's great to know > the potential we have on a modern Linux kernel! > > Later SMB-Direct should be able to reduce the cpu load of the io_wqe_work threads (pipe to socket)... Fantastic results Metze, thanks a *LOT* for sharing this data and also the patches you used to reproduce. Cheers, Jeremy. ^ permalink raw reply [flat|nested] 11+ messages in thread
* Re: Samba with multichannel and io_uring 2020-10-15 9:58 Samba with multichannel and io_uring Stefan Metzmacher 2020-10-15 10:06 ` Ralph Boehme 2020-10-15 15:45 ` Jeremy Allison @ 2020-10-15 16:11 ` Jens Axboe 2020-10-16 11:49 ` Stefan Metzmacher 2 siblings, 1 reply; 11+ messages in thread From: Jens Axboe @ 2020-10-15 16:11 UTC (permalink / raw) To: Stefan Metzmacher, Samba Technical, io-uring On 10/15/20 3:58 AM, Stefan Metzmacher wrote: > Hi, > > related to my talk at the virtual storage developer conference > "multichannel / iouring Status Update within Samba" > (https://www.samba.org/~metze/presentations/2020/SDC/), > I have some additional updates. > > DDN was so kind to sponsor about a week of research on real world > hardware with 100GBit/s interfaces and two NUMA nodes per server. > > I was able to improve the performance drastically. > > I concentrated on SMB2 read performance, but similar improvements would be expected for write too. > > We used "server multi channel support = yes" and the network interface is RSS capable, > it means that a Windows client uses 4 connections by default. > > I first tested a share using /dev/shm and the results where really slow, > it was not possible to reach more than ~30 GBits/s on the net and ~ 3.8 GBytes/s > from fio.exe. > > smbd uses pread() from within a pthread based threadpool for file io > and sendmsg() to deliver the response to the socket. All multichannel > connections are served by the same smbd process (based on the client guid). > > The main smbd is cpu bound and the helper threads also use quite some cpu > about ~ 600% in total! > > https://www.samba.org/~metze/presentations/2020/SDC/future/read-32GBit-4M-2T-shm-sendmsg-top-02.png > > It turns out that NUMA access caused a lot of slow down. > The network adapter was connected to numa node 1, so we pinned > the ramdisk and smbd to that node. > > mount -t tmpfs -o size=60g,mpol=bind:1 tmpfs /dev/shm-numanode1 > numactl --cpunodebind=netdev:ens3f0 --membind=netdev:ens3f0 smbd > > With that it was possible to reach ~ 5 GBytes/s from fio.exe > > But the main problem remains the kernel is busy copying data > and sendmsg() takes up to 0.5 msecs, which means that we don't process new requests > during these 0.5 msecs. > > I created a prototype that uses IORING_OP_SENDMSG with IOSQE_ASYNC (I used a 5.8.12 kernel) > instead of the sync sendmsg() calls, which means that one kernel thread > (io_wqe_work ~50% cpu) per connection is doing the memory copy to the socket > and the main smbd only uses ~11% cpu, but we still use > 400% cpu in total. > > https://www.samba.org/~metze/presentations/2020/SDC/future/read-57GBit-4M-2T-shm-io-uring-sendmsg-async-top-02.png > > But it seems the numa binding for the io_wqe_work thread doesn't seem to work as expected, > so the results vary between 5.0 GBytes/s and 7.6 GBytes/s, depending on which numa node > io_wqe_work kernel threads are running. Also note that the threadpool with pread was > still faster than using IORING_OP_READV towards the filesystem, the reason might also > be numa dependent. > > https://www.samba.org/~metze/presentations/2020/SDC/future/read-57GBit-4M-2T-shm-io-uring-sendmsg-async-numatop-02.png > https://www.samba.org/~metze/presentations/2020/SDC/future/read-57GBit-4M-2T-shm-io-uring-sendmsg-async-perf-top-02.png > > The main problem is still copy_user_enhanced_fast_string, so I tried to use > IORING_IO_SPLICE (from the filesystem via a pipe to the socket) in order to avoid > copying memory around. > > With that I was able to reduce the cpu usage of the main smbd to ~6% cpu with > io_wqe_work threads using between ~3-6% cpu (filesystem to pipe) and > 6-30% cpu (pipe to socket). > > But the Windows client wasn't able to reach better numbers than 7.6 GBytes/s (65 GBits/s). > Only using "Set-SmbClientConfiguration -ConnectionCountPerRssNetworkInterface 16" helped to > get up to 8.9 GBytes/s (76 GBits/s). > > With 8 MByte IOs smbd is quite idle at ~ 5% cpu with the io_wqe_work threads ~100% cpu in total. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-75GBit-8M-20T-RSS16-shm-io-uring-splice-top-02.png > > With 512 KByte IOs smbd uses ~56% cpu with the io_wqe_work threads ~130% cpu in total. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-76GBit-512k-10T-RSS16-shm-io-uring-splice-02.png > > With 256 KByte IOS smbd uses ~87% cpu with the io_wqe_work threads ~180% cpu in total. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-76GBit-256k-10T-RSS16-shm-io-uring-splice-02.png > > In order to get higher numbers I also tested with smbclient. > > - With the default configuration (sendmsg and threadpool pread) I was able to get > 4.2 GBytes/s over a single connection, while smbd with all threads uses ~150% cpu. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-4.2G-smbclient-shm-sendmsg-pthread.png > > - With IORING_IO_SPLICE I was able to get 5 GBytes/s over a single connection, > while smbd uses ~ 6% cpu, with 2 io_wqe_work threads (filesystem to pipe) at 5.3% cpu each + > 1 io_wqe_work thread (pipe to socket) at ~29% cpu. This is only ~55% cpu in total on the server > and the client is the bottleneck here. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-5G-smbclient-shm-io-uring-sendmsg-splice-async.png > > - With a modified smbclient using a forced client guid I used 4 connections into > a single smbd on the server. With that I was able to reach ~ 11 GBytes/s (92 GBits/s) > (This is similar to what 4 iperf instances are able to reach). > The main smbd uses 8.6 % cpu with 4 io_wqe_work threads (pipe to socket) at ~20% cpu each. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-11G-smbclient-same-client-guid-shm-io-uring-splice-async.png > > - With 8 smbclient instances over loopback we are able to reach ~ 22 GBytes/s (180 GBits/s) > and smbd uses 22 % cpu. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-22G-smbclient-8-same-client-guid-localhost-shm-io-uring-splice.png > > So IORING_IO_SPLICE will bring us into a very good shape for streaming reads. > Also note that numa pinning is not really needed here as the memory is not really touched at all. > > It's very likely that IORING_IO_RECVMSG in combination with IORING_IO_SPLICE would also improve the write path. > > Using AF_KCM socket (Kernel Connection Multiplexor) as wrapper to the > (TCP) stream socket might be able to avoid wakeups for incoming packets and > should allow better buffer management for incoming packets within smbd. > > The prototype/work in process patches are available here: > https://git.samba.org/?p=metze/samba/wip.git;a=shortlog;h=refs/heads/v4-13-multichannel > and > https://git.samba.org/?p=metze/samba/wip.git;a=shortlog;h=refs/heads/master-multichannel > > Also notice the missing generic multichannel things via this meta bug: > https://bugzilla.samba.org/show_bug.cgi?id=14534 > > I'm not sure when all this will be production ready, but it's great to know > the potential we have on a modern Linux kernel! > > Later SMB-Direct should be able to reduce the cpu load of the io_wqe_work threads (pipe to socket)... Thanks for sending this, very interesting! As per this email, I took a look at the NUMA bindings. If you can, please try this one-liner below. I'd be interested to know if that removes the fluctuations you're seeing due to bad locality. Looks like kthread_create_on_node() doesn't actually do anything (at least in terms of binding). diff --git a/fs/io-wq.c b/fs/io-wq.c index 74b84e8562fb..7bebb198b3df 100644 --- a/fs/io-wq.c +++ b/fs/io-wq.c @@ -676,6 +676,7 @@ static bool create_io_worker(struct io_wq *wq, struct io_wqe *wqe, int index) kfree(worker); return false; } + kthread_bind_mask(worker->task, cpumask_of_node(wqe->node)); raw_spin_lock_irq(&wqe->lock); hlist_nulls_add_head_rcu(&worker->nulls_node, &wqe->free_list); -- Jens Axboe ^ permalink raw reply related [flat|nested] 11+ messages in thread
* Re: Samba with multichannel and io_uring 2020-10-15 16:11 ` Jens Axboe @ 2020-10-16 11:49 ` Stefan Metzmacher 2020-10-16 12:28 ` Stefan Metzmacher 2020-10-16 15:57 ` Jens Axboe 0 siblings, 2 replies; 11+ messages in thread From: Stefan Metzmacher @ 2020-10-16 11:49 UTC (permalink / raw) To: Jens Axboe, Samba Technical, io-uring [-- Attachment #1.1: Type: text/plain, Size: 2393 bytes --] Hi Jens, > Thanks for sending this, very interesting! As per this email, I took a > look at the NUMA bindings. If you can, please try this one-liner below. > I'd be interested to know if that removes the fluctuations you're seeing > due to bad locality. > > Looks like kthread_create_on_node() doesn't actually do anything (at > least in terms of binding). > > > diff --git a/fs/io-wq.c b/fs/io-wq.c > index 74b84e8562fb..7bebb198b3df 100644 > --- a/fs/io-wq.c > +++ b/fs/io-wq.c > @@ -676,6 +676,7 @@ static bool create_io_worker(struct io_wq *wq, struct io_wqe *wqe, int index) > kfree(worker); > return false; > } > + kthread_bind_mask(worker->task, cpumask_of_node(wqe->node)); > > raw_spin_lock_irq(&wqe->lock); > hlist_nulls_add_head_rcu(&worker->nulls_node, &wqe->free_list); > I no longer have access to that system, but I guess it will help, thanks! With this: worker->task = kthread_create_on_node(io_wqe_worker, worker, wqe->node, "io_wqe_worker-%d/%d", index, wqe->node); I see only "io_wqe_worker-0" and "io_wqe_worker-1" in top, without '/0' or '/1' at the end, this is because set_task_comm() truncates to 15 characters. As developer I think 'io_wqe' is really confusing, just from reading I thought it means "work queue entry", but it's a per numa node worker pool container... 'struct io_wq_node *wqn' would be easier to understand for me... Would it make sense to give each io_wq a unique identifier and use names like this: (fdinfo of the io_uring fd could also include the io_wq id) "io_wq-%u-%u%c", wq->id, wqn->node, index == IO_WQ_ACCT_BOUND ? 'B' : 'U') io_wq-500-M io_wq-500-0B io_wq-500-0B io_wq-500-1B io_wq-500-0U io_wq-200-M io_wq-200-0B io_wq-200-0B io_wq-200-1B io_wq-200-0U I'm not sure how this interacts with workers moving between bound and unbound and maybe a worker id might also be useful (or we rely on their pid) I just found that proc_task_name() handles PF_WQ_WORKER special and cat /proc/$pid/comm can expose something like: kworker/u17:2-btrfs-worker-high ps and top still truncate, but that can be fixed. Some workqueues also expose their details under /sys/bus/workqueue/. I guess there's a lot of potential to optimize the details exposed to the admins and (userspace) developers. metze [-- Attachment #2: OpenPGP digital signature --] [-- Type: application/pgp-signature, Size: 833 bytes --] ^ permalink raw reply [flat|nested] 11+ messages in thread
* Re: Samba with multichannel and io_uring 2020-10-16 11:49 ` Stefan Metzmacher @ 2020-10-16 12:28 ` Stefan Metzmacher 2020-10-16 12:40 ` Stefan Metzmacher 2020-10-16 15:57 ` Jens Axboe 1 sibling, 1 reply; 11+ messages in thread From: Stefan Metzmacher @ 2020-10-16 12:28 UTC (permalink / raw) To: Jens Axboe, Samba Technical, io-uring [-- Attachment #1.1: Type: text/plain, Size: 296 bytes --] > I just found that proc_task_name() handles PF_WQ_WORKER special > and cat /proc/$pid/comm can expose something like: > kworker/u17:2-btrfs-worker-high > > ps and top still truncate, but that can be fixed. I commented on https://gitlab.com/procps-ng/procps/-/issues/51 metze [-- Attachment #2: OpenPGP digital signature --] [-- Type: application/pgp-signature, Size: 833 bytes --] ^ permalink raw reply [flat|nested] 11+ messages in thread
* Re: Samba with multichannel and io_uring 2020-10-16 12:28 ` Stefan Metzmacher @ 2020-10-16 12:40 ` Stefan Metzmacher 2020-10-16 18:56 ` Jens Axboe 0 siblings, 1 reply; 11+ messages in thread From: Stefan Metzmacher @ 2020-10-16 12:40 UTC (permalink / raw) To: Jens Axboe, Samba Technical, io-uring [-- Attachment #1.1: Type: text/plain, Size: 634 bytes --] Am 16.10.20 um 14:28 schrieb Stefan Metzmacher via samba-technical: >> I just found that proc_task_name() handles PF_WQ_WORKER special >> and cat /proc/$pid/comm can expose something like: >> kworker/u17:2-btrfs-worker-high >> >> ps and top still truncate, but that can be fixed. > > I commented on https://gitlab.com/procps-ng/procps/-/issues/51 Ok, it's already fixed in newer versions: https://gitlab.com/procps-ng/procps/-/commit/2cfdbbe897f0d4e41460c7c2b92acfc5804652c8 So it would be great to let proc_task_name() expose more verbose for io-wq tasks in order to avoid the limit of set_task_comm(). metze [-- Attachment #2: OpenPGP digital signature --] [-- Type: application/pgp-signature, Size: 833 bytes --] ^ permalink raw reply [flat|nested] 11+ messages in thread
* Re: Samba with multichannel and io_uring 2020-10-16 12:40 ` Stefan Metzmacher @ 2020-10-16 18:56 ` Jens Axboe 0 siblings, 0 replies; 11+ messages in thread From: Jens Axboe @ 2020-10-16 18:56 UTC (permalink / raw) To: Stefan Metzmacher, Samba Technical, io-uring On 10/16/20 6:40 AM, Stefan Metzmacher wrote: > Am 16.10.20 um 14:28 schrieb Stefan Metzmacher via samba-technical: >>> I just found that proc_task_name() handles PF_WQ_WORKER special >>> and cat /proc/$pid/comm can expose something like: >>> kworker/u17:2-btrfs-worker-high >>> >>> ps and top still truncate, but that can be fixed. >> >> I commented on https://gitlab.com/procps-ng/procps/-/issues/51 > > Ok, it's already fixed in newer versions: > https://gitlab.com/procps-ng/procps/-/commit/2cfdbbe897f0d4e41460c7c2b92acfc5804652c8 > > So it would be great to let proc_task_name() expose more verbose > for io-wq tasks in order to avoid the limit of set_task_comm(). Here's a first cut, format is explained in the last hunk in io-wq. We can't easily get the fd in there, so for sequence, it's just an incrementing long. It shows up in fdinfo as well, so you can match them up. diff --git a/fs/io-wq.c b/fs/io-wq.c index 0c852b75384d..3e2cab10e6f3 100644 --- a/fs/io-wq.c +++ b/fs/io-wq.c @@ -41,6 +41,8 @@ enum { IO_WQE_FLAG_STALLED = 1, /* stalled on hash */ }; +static atomic_long_t seq; + /* * One for each thread in a wqe pool */ @@ -117,6 +119,8 @@ struct io_wq { free_work_fn *free_work; io_wq_work_fn *do_work; + long seq; + struct task_struct *manager; struct user_struct *user; refcount_t refs; @@ -671,7 +675,7 @@ static bool create_io_worker(struct io_wq *wq, struct io_wqe *wqe, int index) spin_lock_init(&worker->lock); worker->task = kthread_create_on_node(io_wqe_worker, worker, wqe->node, - "io_wqe_worker-%d/%d", index, wqe->node); + "io_wq"); if (IS_ERR(worker->task)) { kfree(worker); return false; @@ -1084,6 +1088,7 @@ struct io_wq *io_wq_create(unsigned bounded, struct io_wq_data *data) wq->free_work = data->free_work; wq->do_work = data->do_work; + wq->seq = atomic_long_inc_return(&seq); /* caller must already hold a reference to this */ wq->user = data->user; @@ -1177,3 +1182,39 @@ struct task_struct *io_wq_get_task(struct io_wq *wq) { return wq->manager; } + +long io_wq_get_seq(struct io_wq *wq) +{ + return wq ? wq->seq : 0; +} + +void io_wq_comm(char *buf, size_t size, struct task_struct *task) +{ + struct io_worker *worker = kthread_data(task); + struct io_wqe *wqe; + int off; + + off = strscpy(buf, task->comm, size); + if (off < 0) + return; + + rcu_read_lock(); + if (!io_worker_get(worker)) { + rcu_read_unlock(); + return; + } + rcu_read_unlock(); + + spin_lock_irq(&worker->lock); + wqe = worker->wqe; + + /* + * Format: -seq-node-U/B for bound or unbound. Seq can be found in + * the ring fd fdinfo as well. + */ + scnprintf(buf + off, size - off, "-%ld-%d%c%c", wqe->wq->seq, wqe->node, + worker->flags & IO_WORKER_F_RUNNING ? '+' : '-', + worker->flags & IO_WORKER_F_BOUND ? 'B' : 'U'); + spin_unlock_irq(&worker->lock); + io_worker_release(worker); +} diff --git a/fs/io-wq.h b/fs/io-wq.h index be21c500c925..bede7ab5ac95 100644 --- a/fs/io-wq.h +++ b/fs/io-wq.h @@ -136,6 +136,7 @@ enum io_wq_cancel io_wq_cancel_cb(struct io_wq *wq, work_cancel_fn *cancel, void *data, bool cancel_all); struct task_struct *io_wq_get_task(struct io_wq *wq); +long io_wq_get_seq(struct io_wq *wq); #if defined(CONFIG_IO_WQ) extern void io_wq_worker_sleeping(struct task_struct *); diff --git a/fs/io_uring.c b/fs/io_uring.c index 39c38e48dc11..83df6a326903 100644 --- a/fs/io_uring.c +++ b/fs/io_uring.c @@ -8980,6 +8980,7 @@ static void __io_uring_show_fdinfo(struct io_ring_ctx *ctx, struct seq_file *m) seq_printf(m, "SqThread:\t%d\n", sq ? task_pid_nr(sq->thread) : -1); seq_printf(m, "SqThreadCpu:\t%d\n", sq ? task_cpu(sq->thread) : -1); + seq_printf(m, "WqSeq:\t%ld\n", io_wq_get_seq(ctx->io_wq)); seq_printf(m, "UserFiles:\t%u\n", ctx->nr_user_files); for (i = 0; has_lock && i < ctx->nr_user_files; i++) { struct fixed_file_table *table; diff --git a/fs/proc/array.c b/fs/proc/array.c index 65ec2029fa80..d8f8fbbe9639 100644 --- a/fs/proc/array.c +++ b/fs/proc/array.c @@ -91,6 +91,7 @@ #include <linux/string_helpers.h> #include <linux/user_namespace.h> #include <linux/fs_struct.h> +#include <linux/io_uring.h> #include <asm/processor.h> #include "internal.h" @@ -104,6 +105,8 @@ void proc_task_name(struct seq_file *m, struct task_struct *p, bool escape) if (p->flags & PF_WQ_WORKER) wq_worker_comm(tcomm, sizeof(tcomm), p); + else if (p->flags & PF_IO_WORKER) + io_wq_comm(tcomm, sizeof(tcomm), p); else __get_task_comm(tcomm, sizeof(tcomm), p); diff --git a/include/linux/io_uring.h b/include/linux/io_uring.h index 28939820b6b0..507077f3dac9 100644 --- a/include/linux/io_uring.h +++ b/include/linux/io_uring.h @@ -34,6 +34,7 @@ struct sock *io_uring_get_socket(struct file *file); void __io_uring_task_cancel(void); void __io_uring_files_cancel(struct files_struct *files); void __io_uring_free(struct task_struct *tsk); +void io_wq_comm(char *buf, size_t size, struct task_struct *task); static inline void io_uring_task_cancel(void) { @@ -64,6 +65,9 @@ static inline void io_uring_files_cancel(struct files_struct *files) static inline void io_uring_free(struct task_struct *tsk) { } +static inline void io_wq_comm(char *buf, size_t size, struct task_struct *task) +{ +} #endif #endif -- Jens Axboe ^ permalink raw reply related [flat|nested] 11+ messages in thread
* Re: Samba with multichannel and io_uring 2020-10-16 11:49 ` Stefan Metzmacher 2020-10-16 12:28 ` Stefan Metzmacher @ 2020-10-16 15:57 ` Jens Axboe 2020-10-16 16:03 ` Stefan Metzmacher 1 sibling, 1 reply; 11+ messages in thread From: Jens Axboe @ 2020-10-16 15:57 UTC (permalink / raw) To: Stefan Metzmacher, Samba Technical, io-uring On 10/16/20 5:49 AM, Stefan Metzmacher wrote: > Hi Jens, > >> Thanks for sending this, very interesting! As per this email, I took a >> look at the NUMA bindings. If you can, please try this one-liner below. >> I'd be interested to know if that removes the fluctuations you're seeing >> due to bad locality. >> >> Looks like kthread_create_on_node() doesn't actually do anything (at >> least in terms of binding). >> >> >> diff --git a/fs/io-wq.c b/fs/io-wq.c >> index 74b84e8562fb..7bebb198b3df 100644 >> --- a/fs/io-wq.c >> +++ b/fs/io-wq.c >> @@ -676,6 +676,7 @@ static bool create_io_worker(struct io_wq *wq, struct io_wqe *wqe, int index) >> kfree(worker); >> return false; >> } >> + kthread_bind_mask(worker->task, cpumask_of_node(wqe->node)); >> >> raw_spin_lock_irq(&wqe->lock); >> hlist_nulls_add_head_rcu(&worker->nulls_node, &wqe->free_list); >> > > I no longer have access to that system, but I guess it will help, thanks! I queued up it when I sent it out, and it'll go into stable as well. I since verified on NUMA here that it does the right thing, and that things weren't affinitized properly before. So pretty confident that it will indeed solve this issue! > With this: > > worker->task = kthread_create_on_node(io_wqe_worker, worker, wqe->node, > "io_wqe_worker-%d/%d", index, wqe->node); > > I see only "io_wqe_worker-0" and "io_wqe_worker-1" in top, without '/0' or '/1' at the end, > this is because set_task_comm() truncates to 15 characters. > > As developer I think 'io_wqe' is really confusing, just from reading I thought it > means "work queue entry", but it's a per numa node worker pool container... > 'struct io_wq_node *wqn' would be easier to understand for me... > > Would it make sense to give each io_wq a unique identifier and use names like this: > (fdinfo of the io_uring fd could also include the io_wq id) > > "io_wq-%u-%u%c", wq->id, wqn->node, index == IO_WQ_ACCT_BOUND ? 'B' : 'U') > > io_wq-500-M > io_wq-500-0B > io_wq-500-0B > io_wq-500-1B > io_wq-500-0U > io_wq-200-M > io_wq-200-0B > io_wq-200-0B > io_wq-200-1B > io_wq-200-0U > > I'm not sure how this interacts with workers moving between bound and unbound > and maybe a worker id might also be useful (or we rely on their pid) I don't think that's too important, as it's just a snapshot in time. So it'll fluctuate based on the role of the worker. > I just found that proc_task_name() handles PF_WQ_WORKER special > and cat /proc/$pid/comm can expose something like: > kworker/u17:2-btrfs-worker-high Yep, that's how they do fancier names. It's been on my agenda for a while to do something about this, I'll try and cook something up for 5.11. -- Jens Axboe ^ permalink raw reply [flat|nested] 11+ messages in thread
* Re: Samba with multichannel and io_uring 2020-10-16 15:57 ` Jens Axboe @ 2020-10-16 16:03 ` Stefan Metzmacher 2020-10-16 16:06 ` Jens Axboe 0 siblings, 1 reply; 11+ messages in thread From: Stefan Metzmacher @ 2020-10-16 16:03 UTC (permalink / raw) To: Jens Axboe, Samba Technical, io-uring [-- Attachment #1.1: Type: text/plain, Size: 3154 bytes --] Am 16.10.20 um 17:57 schrieb Jens Axboe: > On 10/16/20 5:49 AM, Stefan Metzmacher wrote: >> Hi Jens, >> >>> Thanks for sending this, very interesting! As per this email, I took a >>> look at the NUMA bindings. If you can, please try this one-liner below. >>> I'd be interested to know if that removes the fluctuations you're seeing >>> due to bad locality. >>> >>> Looks like kthread_create_on_node() doesn't actually do anything (at >>> least in terms of binding). >>> >>> >>> diff --git a/fs/io-wq.c b/fs/io-wq.c >>> index 74b84e8562fb..7bebb198b3df 100644 >>> --- a/fs/io-wq.c >>> +++ b/fs/io-wq.c >>> @@ -676,6 +676,7 @@ static bool create_io_worker(struct io_wq *wq, struct io_wqe *wqe, int index) >>> kfree(worker); >>> return false; >>> } >>> + kthread_bind_mask(worker->task, cpumask_of_node(wqe->node)); >>> >>> raw_spin_lock_irq(&wqe->lock); >>> hlist_nulls_add_head_rcu(&worker->nulls_node, &wqe->free_list); >>> >> >> I no longer have access to that system, but I guess it will help, thanks! > > I queued up it when I sent it out, and it'll go into stable as well. > I since verified on NUMA here that it does the right thing, and that > things weren't affinitized properly before. So pretty confident that it > will indeed solve this issue! Great thanks! >> With this: >> >> worker->task = kthread_create_on_node(io_wqe_worker, worker, wqe->node, >> "io_wqe_worker-%d/%d", index, wqe->node); >> >> I see only "io_wqe_worker-0" and "io_wqe_worker-1" in top, without '/0' or '/1' at the end, >> this is because set_task_comm() truncates to 15 characters. >> >> As developer I think 'io_wqe' is really confusing, just from reading I thought it >> means "work queue entry", but it's a per numa node worker pool container... >> 'struct io_wq_node *wqn' would be easier to understand for me... >> >> Would it make sense to give each io_wq a unique identifier and use names like this: >> (fdinfo of the io_uring fd could also include the io_wq id) >> >> "io_wq-%u-%u%c", wq->id, wqn->node, index == IO_WQ_ACCT_BOUND ? 'B' : 'U') >> >> io_wq-500-M >> io_wq-500-0B >> io_wq-500-0B >> io_wq-500-1B >> io_wq-500-0U >> io_wq-200-M >> io_wq-200-0B >> io_wq-200-0B >> io_wq-200-1B >> io_wq-200-0U >> >> I'm not sure how this interacts with workers moving between bound and unbound >> and maybe a worker id might also be useful (or we rely on their pid) > > I don't think that's too important, as it's just a snapshot in time. So > it'll fluctuate based on the role of the worker. > >> I just found that proc_task_name() handles PF_WQ_WORKER special >> and cat /proc/$pid/comm can expose something like: >> kworker/u17:2-btrfs-worker-high > > Yep, that's how they do fancier names. It's been on my agenda for a while > to do something about this, I'll try and cook something up for 5.11. With a function like wq_worker_comm being called by proc_task_name(), you would capture current IO_WORKER_F_BOUND state and alter the name. Please CC me on your patches in that direction. Thanks! metze [-- Attachment #2: OpenPGP digital signature --] [-- Type: application/pgp-signature, Size: 833 bytes --] ^ permalink raw reply [flat|nested] 11+ messages in thread
* Re: Samba with multichannel and io_uring 2020-10-16 16:03 ` Stefan Metzmacher @ 2020-10-16 16:06 ` Jens Axboe 0 siblings, 0 replies; 11+ messages in thread From: Jens Axboe @ 2020-10-16 16:06 UTC (permalink / raw) To: Stefan Metzmacher, Samba Technical, io-uring On 10/16/20 10:03 AM, Stefan Metzmacher wrote: >> >> I don't think that's too important, as it's just a snapshot in time. So >> it'll fluctuate based on the role of the worker. >> >>> I just found that proc_task_name() handles PF_WQ_WORKER special >>> and cat /proc/$pid/comm can expose something like: >>> kworker/u17:2-btrfs-worker-high >> >> Yep, that's how they do fancier names. It's been on my agenda for a while >> to do something about this, I'll try and cook something up for 5.11. > > With a function like wq_worker_comm being called by proc_task_name(), > you would capture current IO_WORKER_F_BOUND state and alter the name. Oh yes, it'll be accurate enough, my point is just that by the time you see it, reality might be different. But that's fine, that's how they work. > Please CC me on your patches in that direction. Will do! -- Jens Axboe ^ permalink raw reply [flat|nested] 11+ messages in thread
end of thread, other threads:[~2020-10-16 18:56 UTC | newest] Thread overview: 11+ messages (download: mbox.gz follow: Atom feed -- links below jump to the message on this page -- 2020-10-15 9:58 Samba with multichannel and io_uring Stefan Metzmacher 2020-10-15 10:06 ` Ralph Boehme 2020-10-15 15:45 ` Jeremy Allison 2020-10-15 16:11 ` Jens Axboe 2020-10-16 11:49 ` Stefan Metzmacher 2020-10-16 12:28 ` Stefan Metzmacher 2020-10-16 12:40 ` Stefan Metzmacher 2020-10-16 18:56 ` Jens Axboe 2020-10-16 15:57 ` Jens Axboe 2020-10-16 16:03 ` Stefan Metzmacher 2020-10-16 16:06 ` Jens Axboe
This is a public inbox, see mirroring instructions for how to clone and mirror all data and code used for this inbox
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}